LCMC DRBD Installation Debian Wheezy
In diesem Howto möchte ich zeigen wie man mit LCMC DRBD einrichtet.
Dieses Howto baut auf den Artikel LCMC Installation Debian Wheezy auf.
Als erstes werden die Grundeinstellungen für DRBD vorgenommen. Damit wir auch eine gute Performance erzielen.
DRBD Replikation erstellen
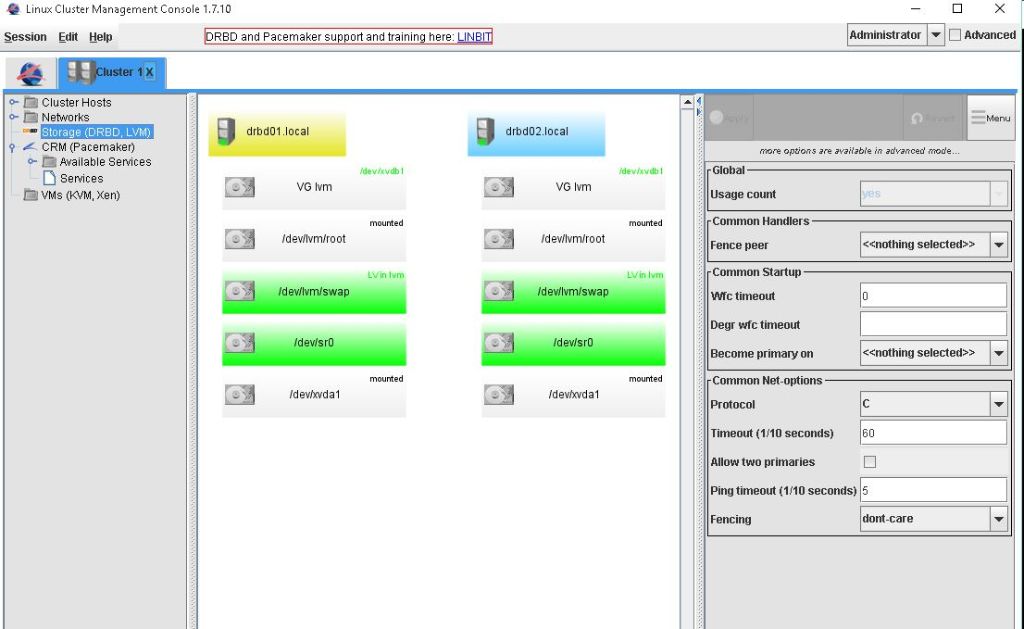
Da unsere Server mit LVM aufgesetzt wurde. Erstellen wir jetzt erst mal ein LV das wir dann Spiegeln werden.
Der Vorteil eines LVM ist das wir das DRBD jederzeit erweitern können.
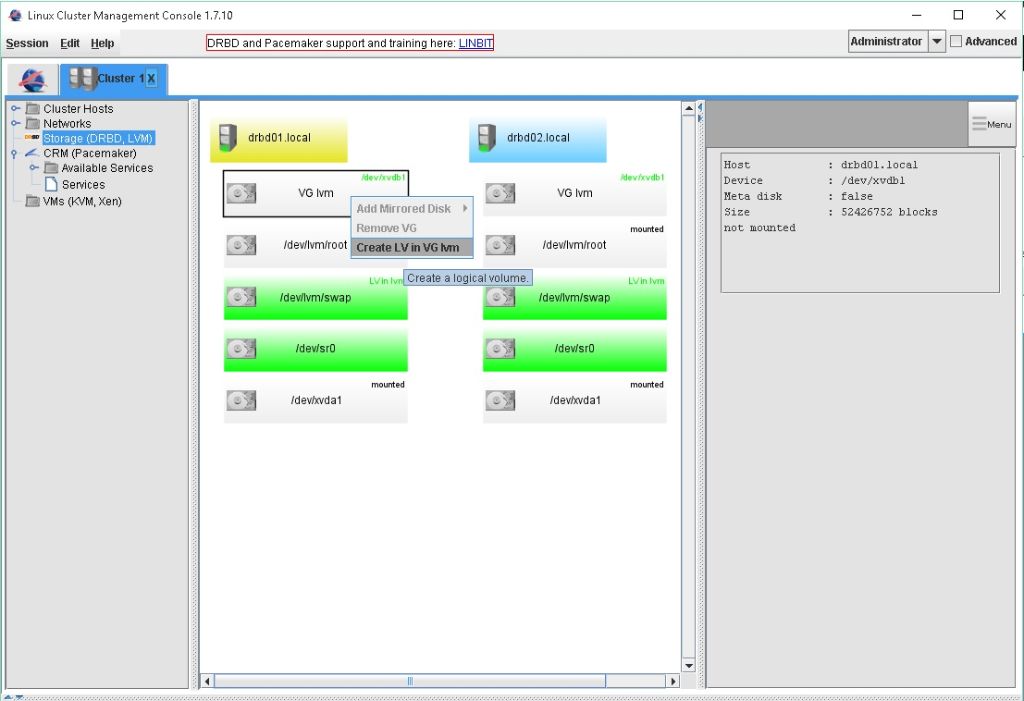
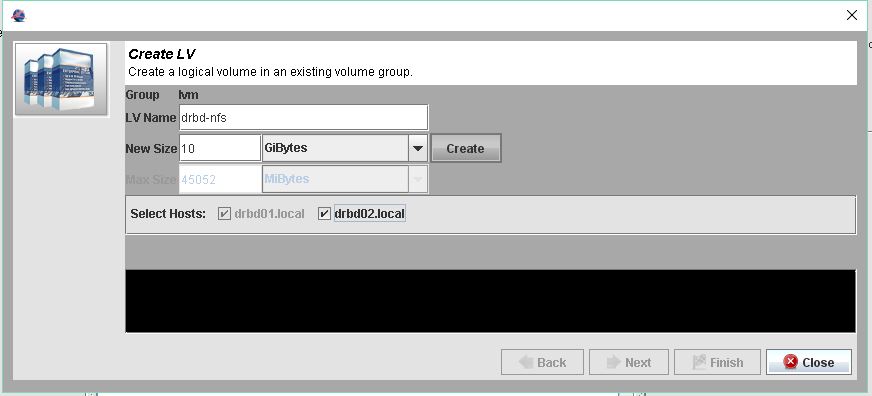
LV Namen und Grüße des LVs angeben. Und den hacken für die zweite Maschine setzten. Dann wird das LV auch gleich auf der zweiten Node erstellt.
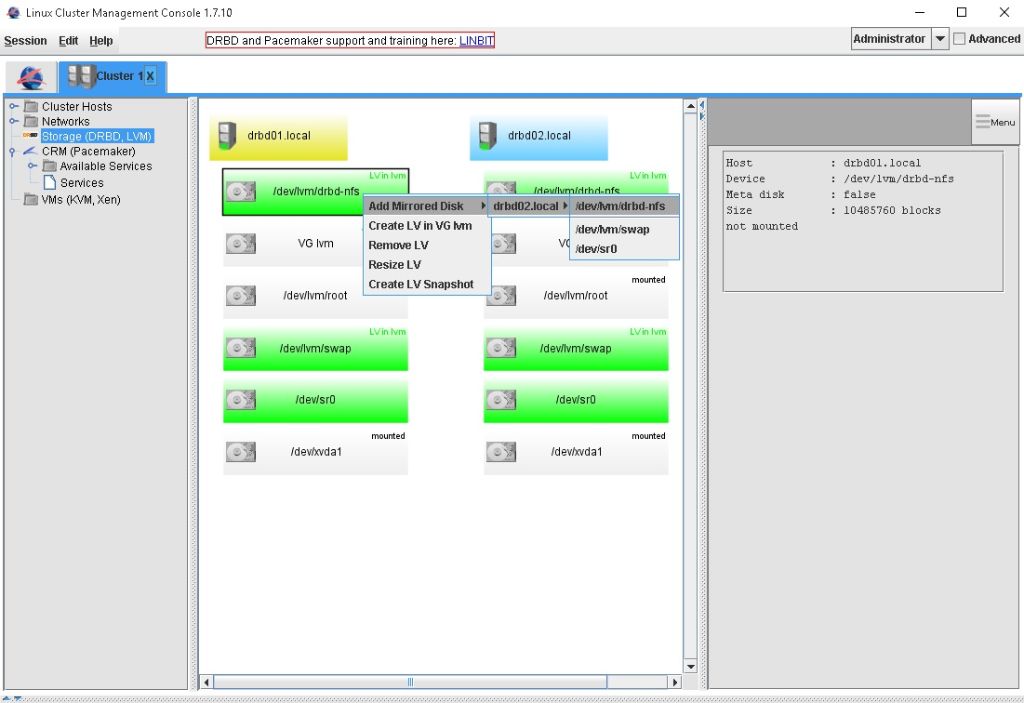
Als nächstes erstellen wir die DRBD Replikation für das gerade angelegte LV
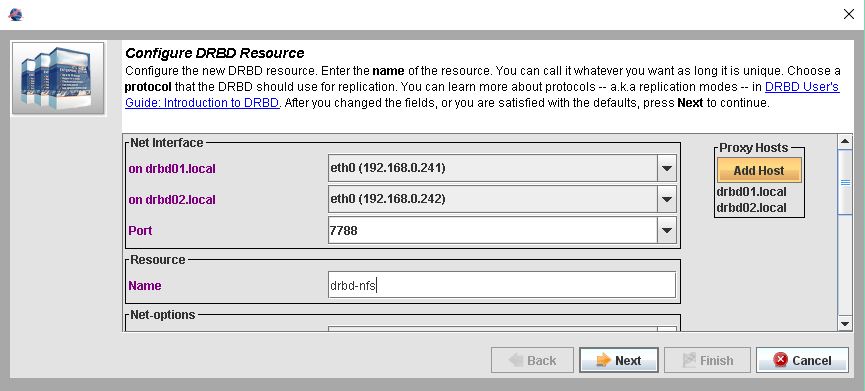
Hier werden wir gefragt über welche Interfaces wir die Replikation betreiben wollen.
Über welchen Port das laufen soll.
Wie der Name der Ressource heißen soll.
Bei Protokoll sollte man B oder C auswählen. Variante C ist die Sicherste. Allerdings hab ich auch gute Erfahrungen mit B gemacht.
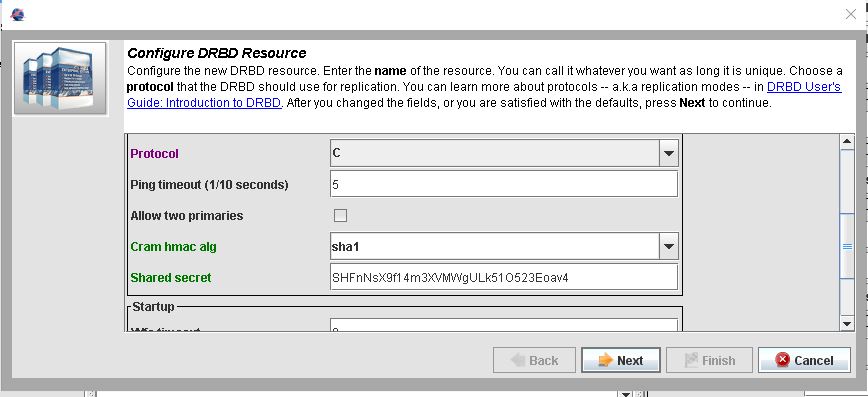
- Protokoll A: asynchronr Replikationsmodus – die Daten gelten als sicher, sobald sie von der lokalen HDD als geschrieben gemeldet und in den TCP-Sendepuffer geschrieben wurden.
- Protokoll B : semi-synchroner Replikationsmodus – die Daten gelten als sicher, sobald sie von der lokalen HDD als geschrieben gemeldet wurden und der DRBD-Partner-Node den Datenempfang bestätigt hat.
- Protokoll C: synchroner Replikationsmodus – die Daten gelten als sicher, sobald sie auf ALLEN beteiligten Platten (lokal und anderer Node) geschrieben wurden.
Bei Wfc timeout und Degr wfc timeout sollte man den wert von 0 auf 60 stellen.
Sonst wartet das DRBD beim Start bis in die Unendlichkeit auf eine Verbindung.
Dadurch konnte ich mich nicht mehr per SSH auf den Server verbinden da der SSH Service erst danach Startete.
Das kann man Standard lassen.
Meda Disk (Daten) auf Internal Stellen und das auch beider zweiten Node
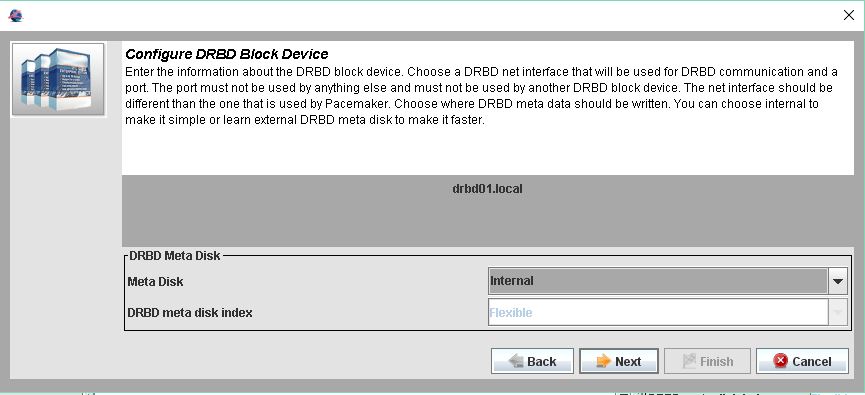
Meta Data erstellen.
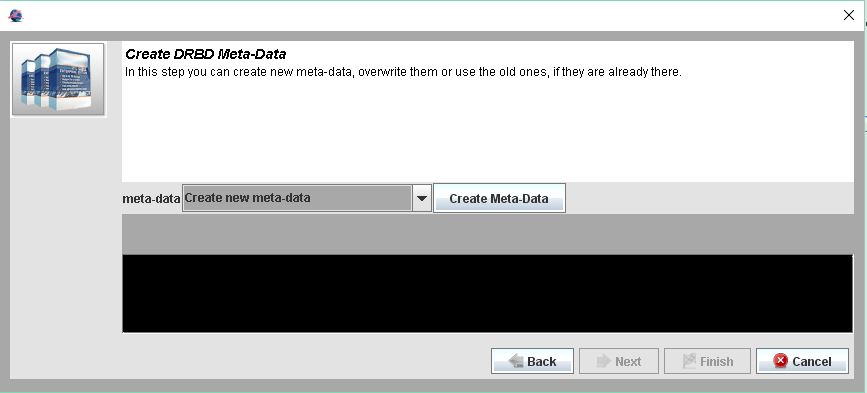
Primary Host auswählen und das Filesystem erstellen.
Ich empfehle hier den Hacken aus skip initial full sync zu nehmen. Also einen full sync machen lassen.
Als Filesystem nehme ich XFS. Aber man kann auch andere auswählen.
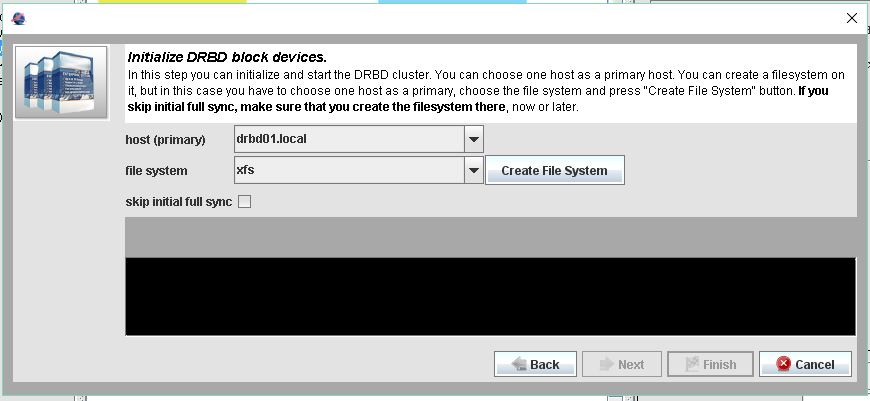
Im Anschluss kann man sehen das der Sync angefangen hat.
In der Console kann man das mit diesem Befehl machen
[stextbox id=“bash“]cat /proc/drbd[/stextbox]
[stextbox id=“black“]version: 8.4.3 (api:1/proto:86-101)
srcversion: 1A9F77B1CA5FF92235C2213
0: cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent C r—–
ns:775957 nr:0 dw:10573 dr:766331 al:7 bm:46 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:9710304
[>……………….] sync’ed: 7.5% (9480/10236)Mfinish: 0:06:03 speed: 26,728 (17,612) K/sec[/stextbox]
Synchronisierung pausieren und fortsetzen
Man kann die Synchronisierung auch pausieren lassen.
Übers LCMC
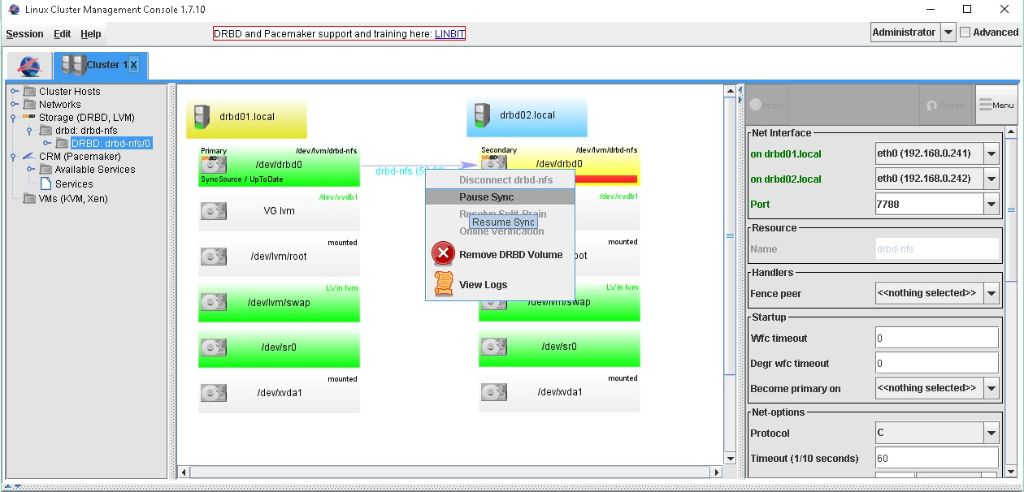
Über die Console
Dies Pausiert die Synchronisation
[stextbox id=“bash“]drbdadm pause-sync drbd-nfs/0[/stextbox]
Und hiermit kann man die Synchronisation weiterlaufen lassen.
[stextbox id=“bash“]drbdadm resume-sync drbd-nfs/0[/stextbox]
Einstellungen Anpassen
Im Advanced Modus sollte man folgende Einstellungen noch anpassen. Das ganze am besten in den Globalen Einstellung vornehmen . Oben Rechts auf Storage klicken.
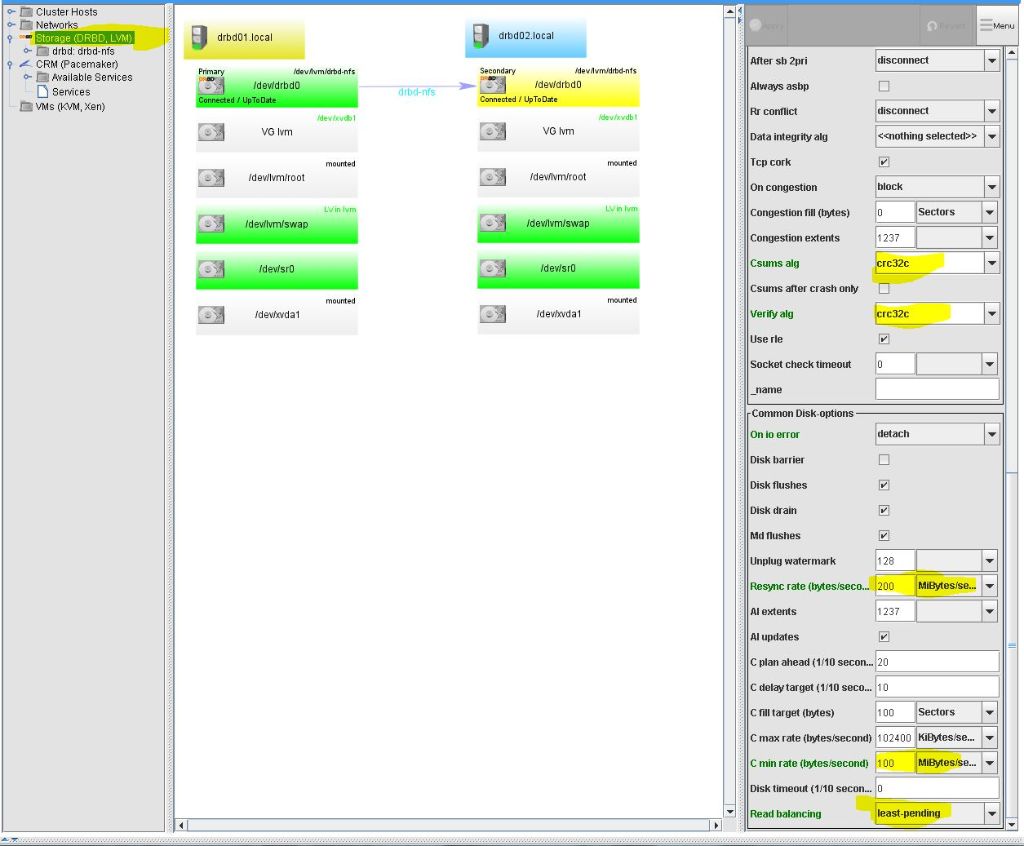
Alternative kann man dies auch für jedes einzelne DRBD Volumen machen.
- csums-alg = Algorithmus für den Sync Prozess. Wenn ein Algorithmus angegeben wird, wird auf beiden Seiten die Blöcke geprüft und nur die übertragen wo sich die Checksum unterscheidet. Dadurch wird auf kosten der CPU die Bandbreite geschont.
- einen Algorithmus auswählen oder auch nicht. Ich nutze hier crc32c
- verify-alg = Algorithmus für die Online Datenprüfung
- einen Algorithmus auswählen. Ich nutze hier crc32c
- resync-rate = Bandbreite für den Sync der Daten.
- von 250 KiByte auf 200 MiByte stellen
- c-min-rate = minimale Bandbreite für den Sync Prozess
- von 250 KiByte auf 100 MiByte stellen
Optional
- read-balancing auf least-pending einstellen.
- Weitere Informationen findet man auch hier
DRBD Automatic split brain recovery policies
Damit DRBD eine Split Brain Situation automatisch beheben kann, kann man ein paar Einstellungen vornehmen.
Mehr Informationen zu diesem Thema findet man auf der DRBD Seite.
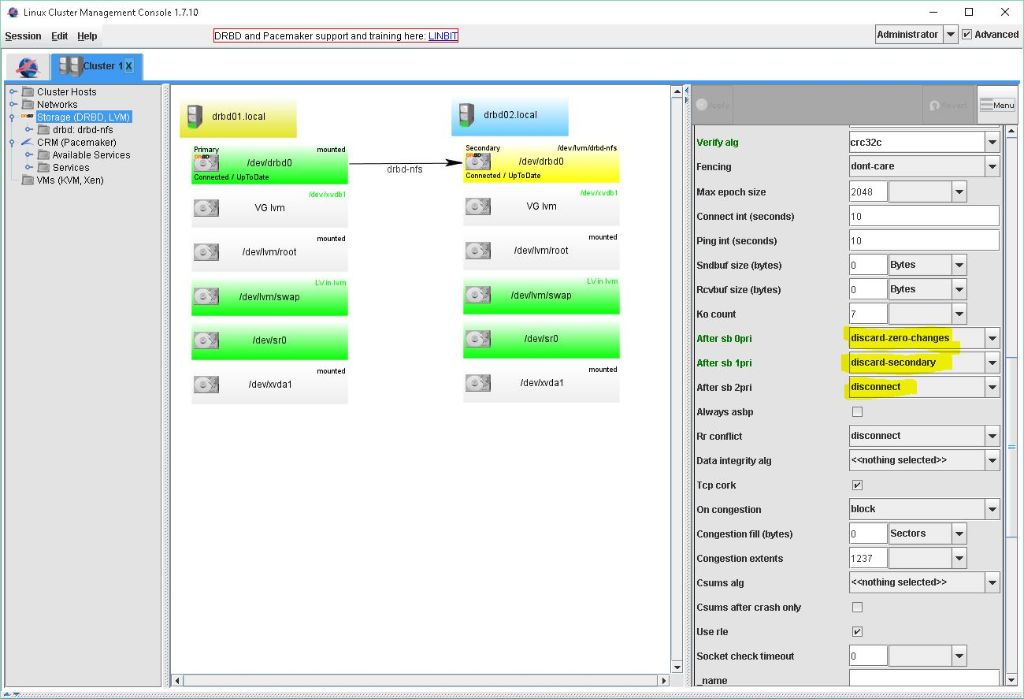
after-sb-0pri. Split Brain wurde erkannt, aber keine Node hat die Primary Role.
DRBD kann folgende Funktionen nun nutzen:
- disconnect: Keine automatische Reparatur / Recover. Stoppe die Verbindung und verwende das split-brain Script falls es konfiguriert ist.
- discard-younger-primary: Verwerfe alle gemachten Modifikationen und Hole die Daten von der Node, die als letztes Primary war/ist.
- discard-least-changes: Verwerfe alle gemachten Modifikationen und Hole die Daten von der Node, wo weniger Änderungen aufgetreten sind.
- discard-zero-changes: Wenn keine Modifikationen auf beiden Nodes gemacht wurden, übernehme diese auf beiden Nodes und mache weiter.
after-sb-1pri. Split Brain wurde erkannt, und dieses mal ist eine Node in der Primary Role.
DRBD kann folgende Funktionen nun nutzen:
- disconnect: Keine automatische Reparatur / Recover. Stoppe die Verbindung und verwende das split-brain Script falls es konfiguriert ist.
- consensus: Verwende die gleich Recovery Policy wie bei after-sb-0pri. Wenn eine Reparatur möglich ist dann mach weiter, ansonsten trenne die Verbindung.
- call-pri-lost-after-sb: Verwende die gleich Recovery Policy wie bei after-sb-0pri. Wenn eine Reparatur möglich ist dann verwende das pri-lost-after-sb Script auf der Node die verloren hat. Dieses Script muss hinterlegt sein.
- discard-secondary: Unabhängig davon, welche Node gerade in der Secondary Role ist, mach diese Node zum Verlierer.
after-sb-2pri. Split brain wurde erkannt, und dieses mal sind beide Nodes in der Primary Role.
Hier Akzeptiert DRBD die gleichen Funktionen wie bei after-sb-1pri außer discard-secondary und consensus.
Jetzt hat man eine Replikation der Festplatte. Aber damit noch lange keinen Cluster / Hochverfügbarkeit.
Im nächsten Howto erstellen wir den DRBD Cluster.